| Activities | Timing and Details |
| Main Sessions | Meets every Monday and Wednesday evening; from 7 PM PST |
| Lab access | Lab hardware resources are available 24/7 for the duration of the course. |
| Help sessions | Every day by appointment. |
| Lab solutions walkthrough | The teaching staff AI engineers will announce their sessions on an ongoing basis. |
| Quiz | There will be two quizzes on each topic. The teaching AI engineers will hold review sessions to explain the solutions. |
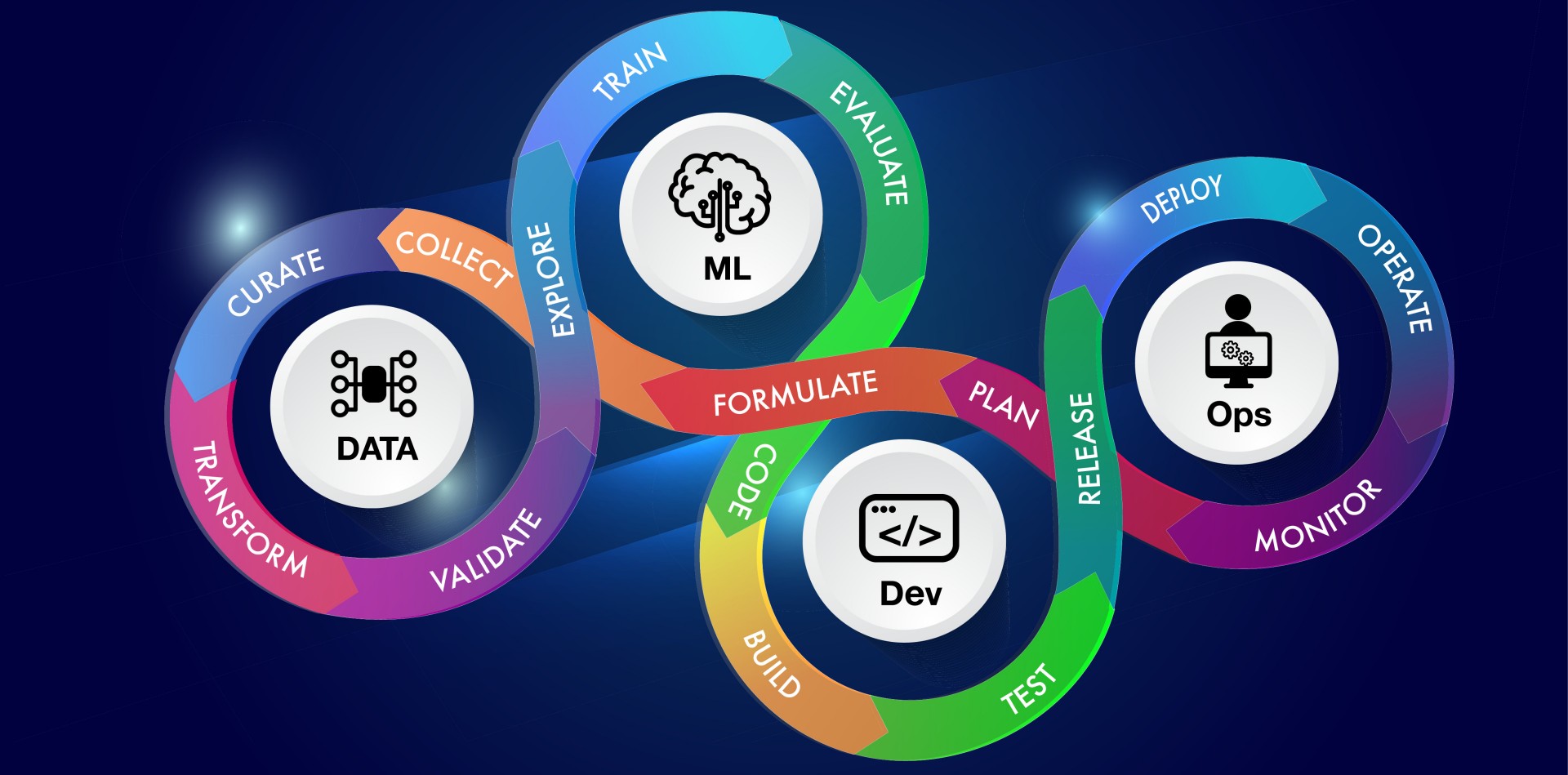
In today's technological landscape, mastering Machine Learning Operations (MLOps) and Large Language Model Operations (LLMOps) is essential for driving innovation and efficiency. This course offers a comprehensive exploration of MLOps and LLMOps, equipping participants with the knowledge and skills to streamline workflows, optimize deployments, and ensure robust model management in enterprise settings.
Course Topics:
- What is MLOps and why does it matter?
MLOps involves deploying and maintaining machine learning models in production reliably and efficiently. It bridges data science and operations, enhancing operational efficiency and model scalability.
- What is LLMOps?
LLMOps extends MLOps principles to large language models, focusing on model fine-tuning, efficient inference, and handling computational requirements.
- MLOps Architecture and Workflows
Understand key components of MLOps architecture, including data pipelines, model training workflows, and deployment strategies. Learn about tools like Jenkins, Airflow, MLFlow, Kyte, and Kubeflow.
- Kubernetes
Learn Kubernetes fundamentals for managing containerized applications and deploying machine learning models at scale.
- Feature Stores and Model Management
Explore the role of feature stores in managing features and best practices for model management and storage, ensuring versioning and reproducibility.
- Ray Framework
Discover the Ray framework for scaling machine learning applications, including Ray Data, Ray Train, and Ray Serve.
- Scalable Model Inference
Key considerations in designing scalable inference serving solutions, optimizing performance, and managing resources.
- NVidia Triton and TensorRT
Leverage NVidia Triton and TensorRT for efficient model inference serving in resource-intensive scenarios.
- Observability
Implement best practices for monitoring, logging, and metrics tracking to maintain model health and performance.
- Model Security
Ensure model security with tools like LlamaGuard, focusing on threat detection and vulnerability assessment.
By the end of this course, participants will be equipped to implement MLOps and LLMOps effectively, enhancing the efficiency, scalability, and security of their machine-learning workflows and driving greater value in their enterprise settings.
 Registration
Registration
Reserve your enrollment now. By the end of the first week of the course, pay the rest of the tuition by Zelle or check.
Financial Aid:
- A 50% discount for registrants from developing nations in Asia or Africa.
- Installment payment plans are available. Reach out to us by email or phone to discuss and get approval.
- Special discount (25% to 100%) for people with disabilities.
- Special discount for veterans
- Teacher: Asif Qamar
